
So you trained your large language model on the entire sum of human knowledge available online, now what? Your model works well internally. If you prompt it to act like a sentient being, it does that scarily well. But how do you let everyone else in? How do you design a system that can serve thousands of concurrent users? That is where Model Inference comes in.
I first heard that word in HBO’s Silicon Valley when Gilfoyle talks about Son of Anton as their new Inference API. And the engineering behind it is fascinating.
But before we get into the optimizations and clever system design tricks, it helps to understand why inference is hard in the first place. Not “hard” in a vague sense, but hard in a specific, measurable, GPU-sits-idle-while-you-pay-for-it sense.
TL;DR
- LLMs generate one token at a time. Every output is hundreds of sequential forward passes.
- Naive static batching wastes GPU compute on padding and idles on slow requests.
- Continuous batching (Orca) fixes throughput by processing iteration-by-iteration, not batch-by-batch.
- PagedAttention (vLLM) fixes memory by treating KV cache like OS virtual memory pages (near-zero fragmentation)
- A Scheduler, Memory Manager, and Engine form the tight loop that makes it all run.
Why Inference is Harder Than It Looks
When you prompt a language model, the output is generated one token at a time. The model does not produce the full response in a single forward pass. Each new token is generated by running the transformer again, with the entire context, i.e., your prompt plus all previously generated tokens, as input. The sequential, autoregressive nature is the root of almost every systems challenge in LLM serving.
Consider what happens on a single GPU: a user sends a prompt of 200 tokens, the model generates 300 tokens in response, one at a time, and each of those 300 forward passes must complete before the next begins. While this is happening, other users are waiting.
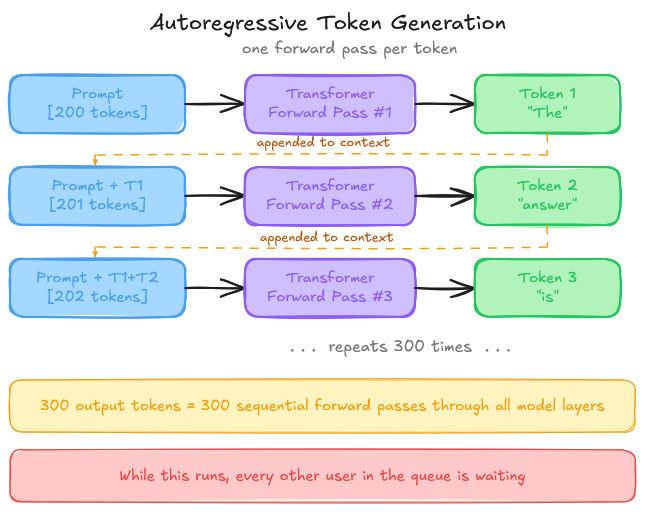
Now add more users. Longer contexts. Requests that vary wildly in both input length and output length. Suddenly, you are not doing ML anymore; you are doing OS work. Suddenly, the ML isn’t the hard part, but making the systems work is.
Memory Management. Scheduling. Concurrency. The model is almost incidental.
That is the problem inference engines exist to solve.
The Naive Implementation: Where It Breaks
The simplest possible serving strategy is static batching: collect a fixed number of requests, process them together as a batch, return results, repeat.
Static batching works. But it wastes enormous amounts of GPU capacity.
The padding problem. In a batch, every sequence must be padded to the length of the longest sequence. If one request generates 500 tokens and three others generate 50, you are doing 10x more computation than necessary for shorter requests. The GPU is doing real work to produce tokens that will be thrown away.

The head-of-line blocking problem. A batch cannot be completed until every sequence in it finishes. One slow request, a long generation, a complex prompt - holds up everything behind it. GPU utilization craters while the slow request finishes, even if the other sequences in the batch are long done.

The memory problem. This is subtle but critical. During inference, the transformer computes and caches key-value (KV) vectors for every token in the sequence. These KV caches must be kept in GPU memory for the duration of the request. For a large model with a long context, a single request can consume gigabytes of VRAM. Under static batching, that memory is reserved upfront and held for the entire request lifetime, even during the decoding steps where most of the memory is idle.
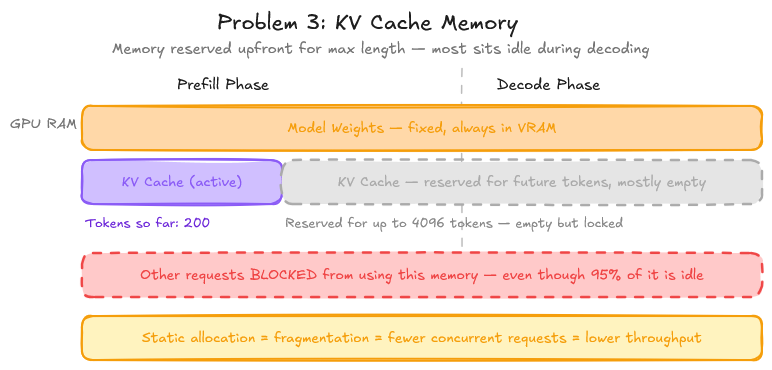
KV Cache: The Central Resource
Before going further, the KV cache deserves its own section because it is the resource that every major optimization in modern inference is ultimately about.
During a transformer forward pass, each attention layer computes queries (Q), keys (K), and values (V) for every token. The fundamental insight is: for tokens you have already seen, you do not need to recompute K and V. You computed them in the last step. Cache them.
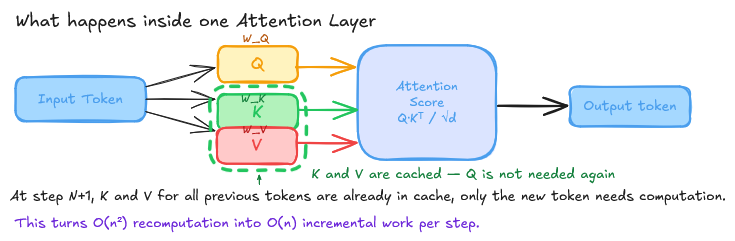
This is the KV cache. Without it, inference at any practical context length would be ridiculously slow.
The problem is size.
For a model like Llama 3 70B, each KV cache entry for a single token requires:

Under the naive approach, this memory is pre-allocated contiguously for each request, up to the maximum possible sequence length. Which means you are reserving memory for tokens that may never be generated. This means you can fit far fewer requests in memory than the GPU can theoretically handle. As a result, throughput suffers.

Continuous Batching: Fixing the Throughput Problem
The solution to the static batching inefficiencies came from a 2022 paper from UC Berkeley - Orca (A Distributed Serving System for Transformer-Based Generative Models).
The key insight is pretty simple: instead of waiting for an entire batch to finish, process requests iteration by iteration, and swap finished requests out of the batch immediately.
In continuous batching, the scheduler runs on every generation step, not every batch:
- At each iteration, look at which sequences in the current batch just finished (hit an EOS token or max length).
- Immediately remove those sequences from the batch.
- Pull waiting requests from the queue and add them to the batch.
- Run the next forward pass.
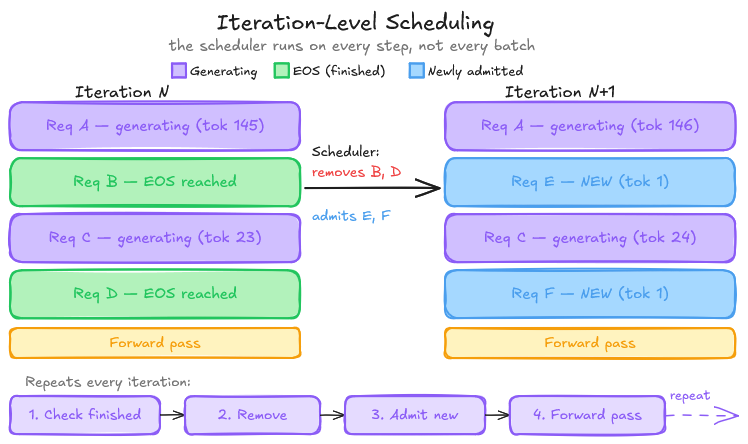
GPU utilization goes from spending half its time waiting for slow requests to finish, to continuously processing work. Short requests do not wait behind long ones. The batch stays full.
In static batching, all sequences in a batch are at the same “position.” You run the full prefill for everyone, then decode together. In continuous batching, different sequences in the same batch are at different positions. Some are on token 3 of the generation. Some are on token 300. The attention computation must handle this correctly. Modern inference frameworks handle this via variable-length attention kernels (Flash Attention with sequence masking), but it is non-trivial to implement from scratch.
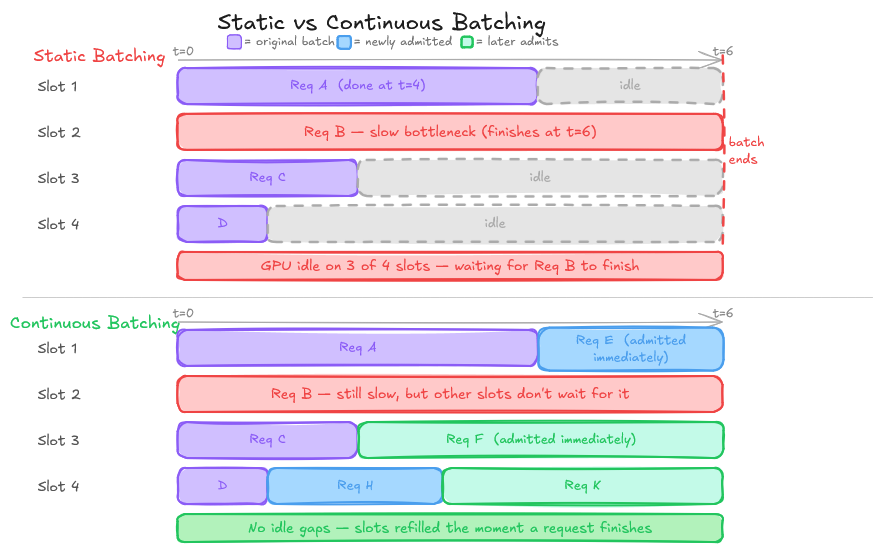
The core loop is: evaluate current batch state → retire finished sequences → admit new sequences → dispatch forward pass. Even without optimized attention kernels, the structural pattern is the same.
PagedAttention: Fixing the Memory Problem
Continuous batching dramatically improves throughput. But it does not solve the memory fragmentation problem. KV caches are still pre-allocated contiguously per request, causing internal fragmentation (reserving memory for future tokens that may not arrive) and external fragmentation (gaps between allocations that cannot be reused).
The solution came from the same Berkeley group in 2023: Efficient Memory Management for Large Language Model Serving with PagedAttention (Kwon et al.), and the system built on it: vLLM.
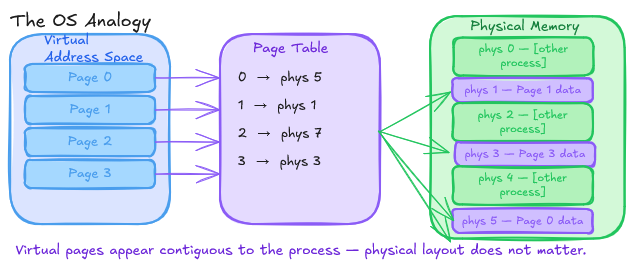
The core idea is borrowed from operating systems’ virtual memory: treat KV cache memory as pages, not as contiguous buffers.
In a traditional OS, physical memory is divided into fixed-size pages (often 4KB). Processes see a contiguous virtual address space, but the underlying physical memory can be fragmented; non-contiguous pages are mapped through a page table. This separation allows the OS to pack memory tightly without requiring contiguous physical allocation.
PagedAttention applies the same idea to KV cache:
- GPU memory is divided into fixed-size KV blocks, each holding the KV vectors for a fixed number of tokens (a “block size”, e.g., 16 tokens).
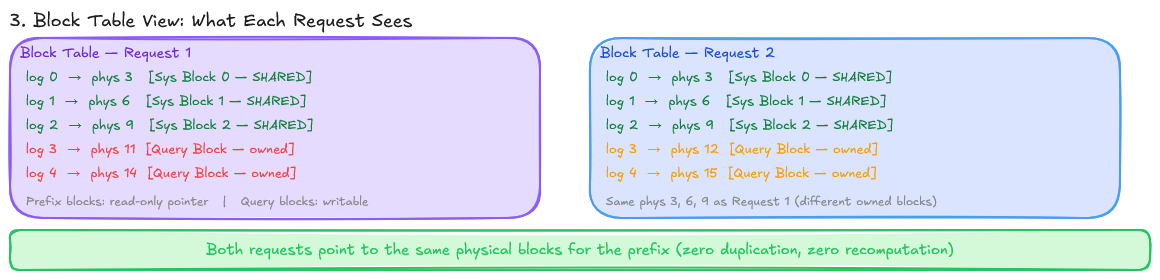
- Each request gets a block table: a mapping from logical block indices to physical block indices in GPU memory.
- As a request generates new tokens, it acquires new physical blocks on demand. Blocks can be physically non-contiguous.
- When a request finishes, its blocks are freed and immediately available for new requests.
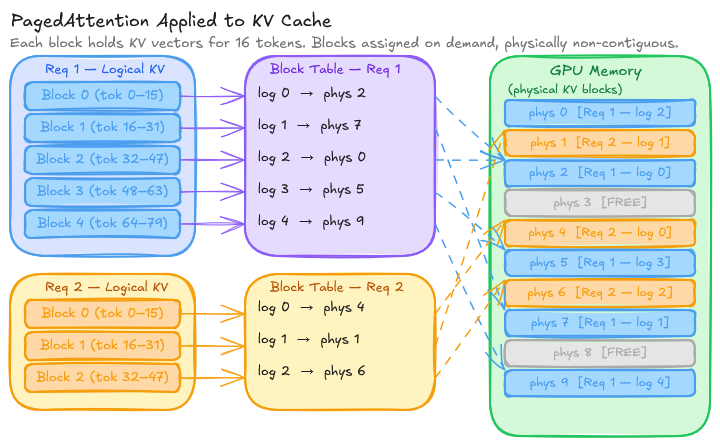
The result: near-zero memory fragmentation. In the original vLLM paper, PagedAttention achieves 4% memory waste compared to 60–80% waste in prior systems. That means the same GPU can fit significantly more concurrent requests, which directly translates to throughput.
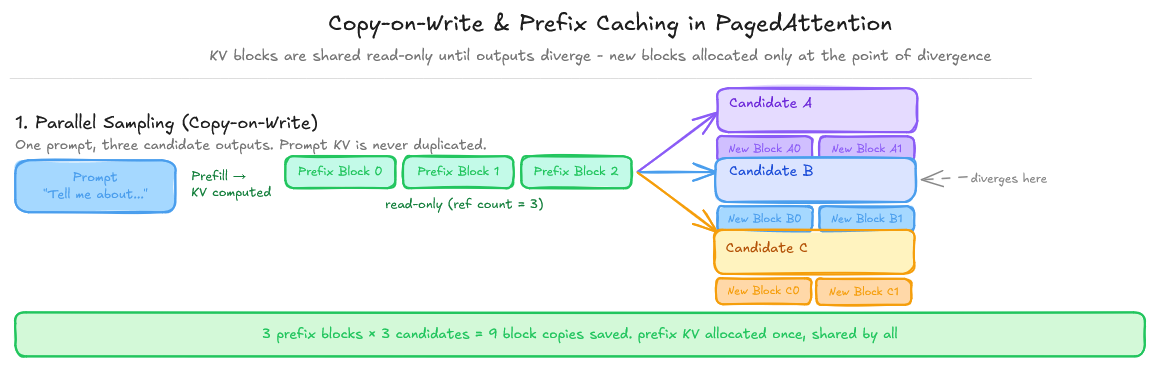
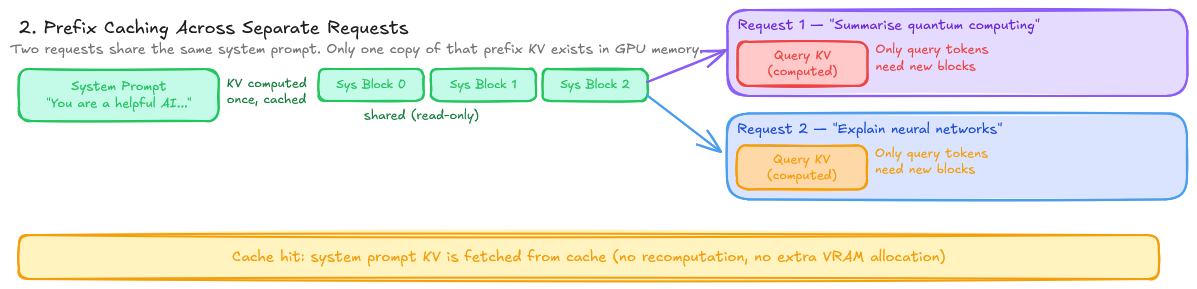
A secondary benefit: copy-on-write for KV cache sharing. In parallel sampling (generating multiple candidate outputs for one prompt), the prompt’s KV cache can be shared across all candidates as read-only, with new blocks only allocated when divergence occurs. The same mechanism enables prefix caching. If two requests share a common prompt prefix, their KV cache for that prefix can be shared.
How It's Structured: The Layers of an Inference Engine
Continuous batching and PagedAttention are what. The inference engine is the system that actually implements them. Modern inference engines like vLLM are organized into three core internal layers.
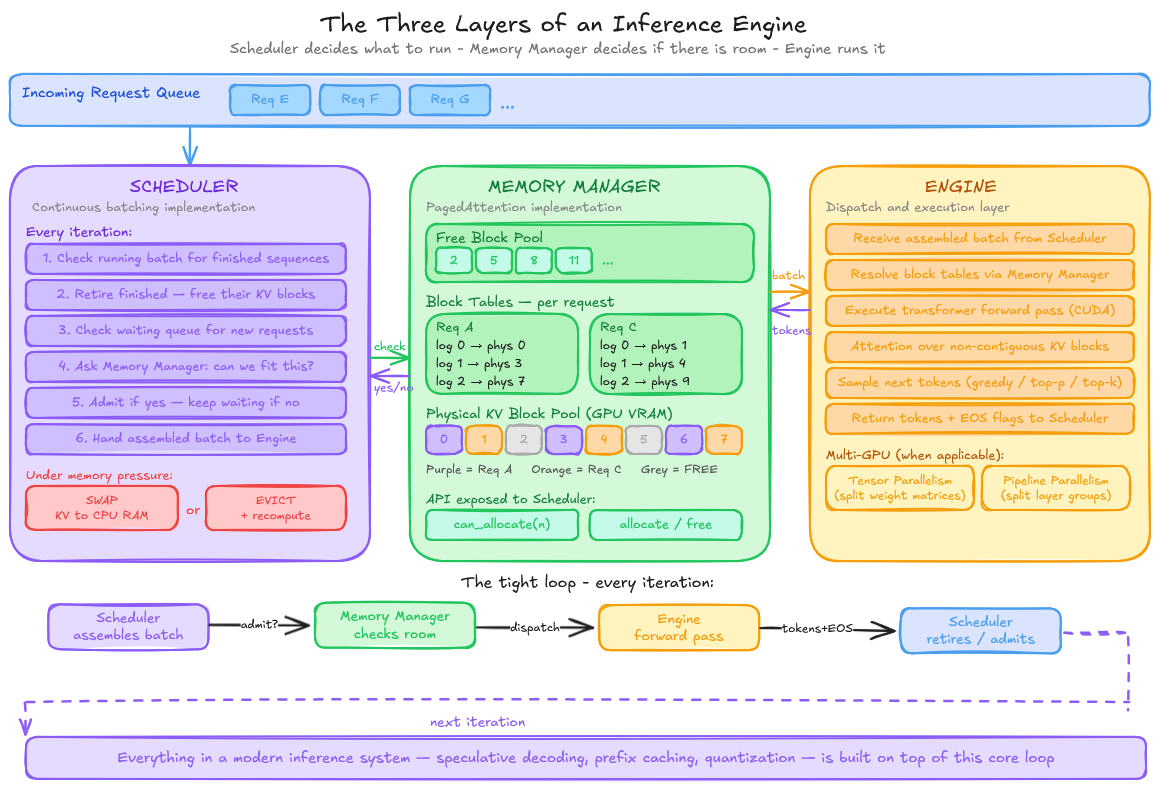
Memory Manager. This is the PagedAttention implementation. It maintains a pool of fixed-size KV blocks in GPU memory, a free list of available blocks, and a block table per request mapping logical token positions to physical blocks.
When a request needs more memory, the Memory Manager allocates a new block from the free list. When a request finishes, it returns its blocks. Every admission decision, “Can we fit this new request?” runs through the Memory Manager first.
Scheduler. This is the continuous batching implementation. The Scheduler runs at every iteration: it examines the running batch, retires finished sequences, checks the waiting queue, and admits new requests, subject to the Memory Manager’s availability check. It also handles preemption. When a running request can no longer be served due to memory pressure, the Scheduler decides whether to swap its KV cache to CPU memory or evict it entirely and recompute from the original prompt.
Engine. The dispatch layer. It takes the batch the Scheduler has assembled and executes the actual forward pass through the model, managing CUDA kernel calls, tensor operations, and sampling. In multi-GPU setups, the Engine also coordinates tensor and pipeline parallelism across devices. It is the layer closest to the hardware. The Scheduler and Memory Manager do the hard thinking so the Engine can focus on throughput.
These three layers form a tight loop: the Scheduler decides what to run, the Memory Manager decides if there is room, and the Engine runs it. Everything else in a modern inference system is built on top of this core.
The Scheduler: Putting It Together
Continuous batching tells you how to process requests. PagedAttention tells you how to manage memory. The scheduler is what connects them. It decides which requests run, in what order, and what happens when memory runs out.
A production scheduler manages several competing concerns:
Admission control. Before admitting a request to the running batch, the scheduler checks whether enough free KV cache blocks exist to serve it. If not, the request waits in a queue. This prevents OOM (Out of Memory) crashes that would otherwise kill the entire serving process.
Preemption. What happens when a batch is running, and memory runs out mid-generation (because requests are generating longer than expected)? There are two strategies:
- Swapping: Move the evicted request’s KV cache blocks from GPU to CPU memory, and swap them back when space is available. High memory overhead adds PCIe transfer latency.
- Recomputation: Evict the request entirely, discard its KV cache, and recompute from the original prompt when rescheduled. Wasteful in computation, but it avoids the CPU memory requirement.
vLLM supports both strategies. The right choice depends on the workload. Swap for long contexts where recomputation is expensive, recompute for short prompts.
Priority scheduling. Not all requests are equal. A production system might assign priority based on SLA tier, request age, or estimated output length. The scheduler implements a priority queue and can preempt lower-priority requests to serve high-priority ones.
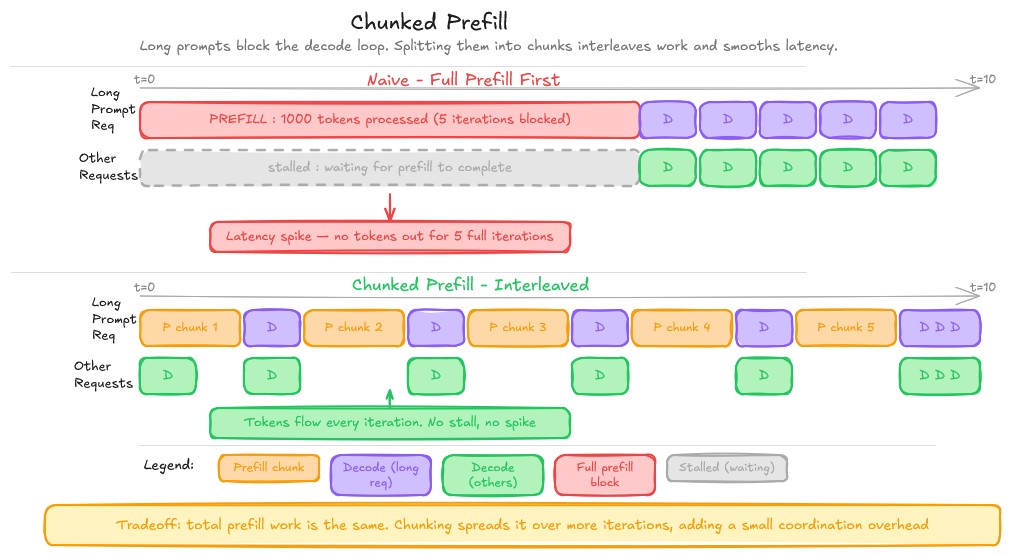
Chunked prefill. For very long prompts, the prefill phase (processing the input tokens) can itself be expensive enough to introduce latency spikes. Chunked prefill splits the prompt into chunks, interleaving prefill steps with decode steps across multiple iterations. This smooths out latency at the cost of some additional complexity.
The Full Request Lifecycle
Putting it all together, here is what happens from the moment a request arrives to the moment the last token is returned:
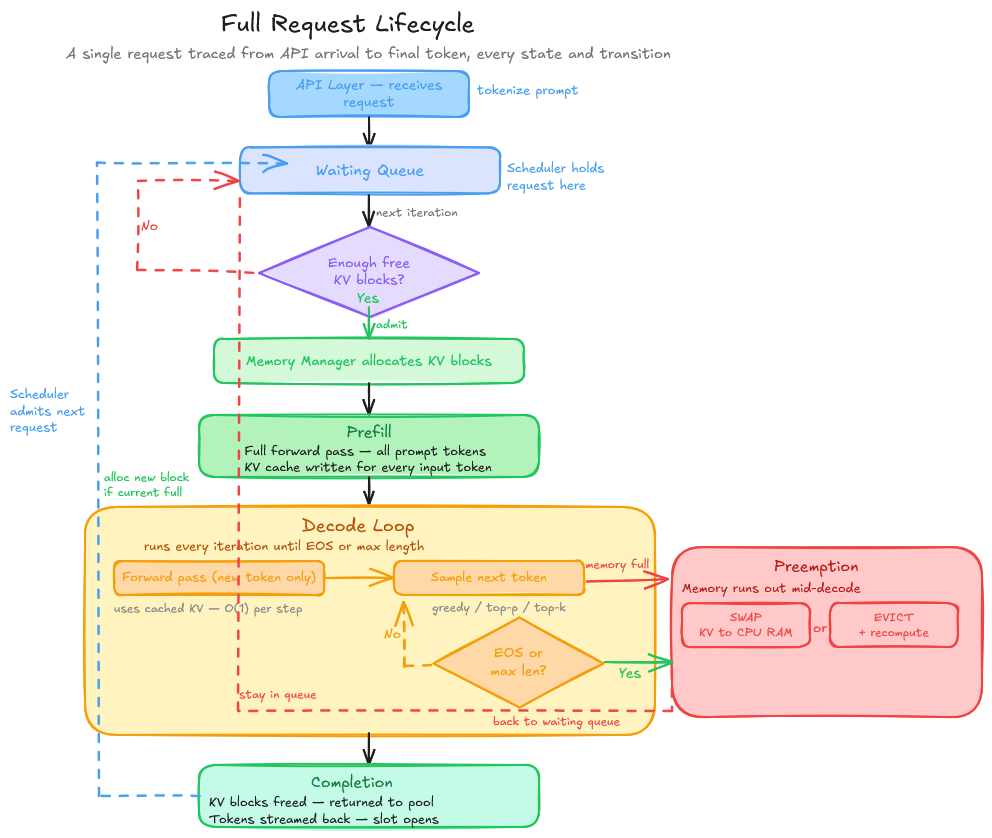
1. Arrival → Queue: The API layer receives the request, tokenizes the prompt, and hands it to the scheduler. The scheduler places it in the waiting queue.
2. Admission: On the next scheduling iteration, the scheduler checks the waiting queue. If enough free KV cache blocks are available to handle the prompt’s prefill, the request is moved to the running batch.
3. Prefill: The engine runs a single forward pass over the entire prompt. This is compute-heavy but memory-predictable. You know exactly how many KV blocks you need. The KV cache for all prompt tokens is computed and stored in the allocated blocks.
4. Decode loop: Now the autoregressive generation begins. Each iteration:
- The scheduler checks which sequences are running, finished, or preempted.
- A new block is allocated if the running request has filled its current block.
- The engine runs a forward pass over the new token(s) only, using the cached KV vectors for all previous tokens.
- The new token is sampled (greedy, top-p, etc.) and returned.
- If the token is EOS or max length is hit, the request is marked finished.
5. Completion: The sequence is removed from the running batch. Its KV cache blocks are freed. The scheduler immediately considers new requests for admission. The API layer streams or returns the generated tokens.
This loop runs continuously, every iteration, for every request in the system. At scale, hundreds of sequences are in this loop simultaneously, their KV caches spread across non-contiguous physical blocks, the scheduler juggling admissions and completions thousands of times per second.
What the Real Systems Add On Top
The architecture described above: continuous batching + PagedAttention + a scheduler, is the core of vLLM. Production systems like TensorRT-LLM and DeepSpeed-FastGen layer additional optimizations on top:
Tensor parallelism. For models too large for a single GPU, split each weight matrix across multiple GPUs. Each GPU handles a slice of the computation; results are aggregated via all-reduce. Requires tight synchronization but scales linearly with GPU count for the right layer types.
Pipeline parallelism. Split the model’s layers across GPUs in a pipeline. GPU 1 handles layers 1-20, GPU 2 handles layers 21-40, and so on. Different requests can be in different pipeline stages simultaneously, improving GPU utilization.
Speculative decoding. Use a small draft model to generate multiple tokens speculatively, then verify them in a single forward pass of the large model. If the large model agrees, you get multiple tokens for the cost of roughly one forward pass. Very effective for long outputs with a predictable structure.
Post-training quantization. INT8 and INT4 quantization reduce both memory footprint and compute, without touching the training process. GPTQ, AWQ, and SqueezeLLM are the dominant schemes: all three take a fully trained model and compress its weights after the fact, trading a small amount of accuracy for significantly lower memory and faster arithmetic. The inference engine must have kernels explicitly optimized for quantized matrix multiplications. Casting weights to INT4 and running standard CUDA kernels does not work. The hardware savings only materialize when the compute path is built end-to-end.
Custom attention kernels. Flash Attention and Flash Attention 2 dramatically reduce memory bandwidth usage during the attention computation by fusing operations and using tiling. Flash Attention 3, released in 2024, further optimizes for Hopper architecture (H100). These kernels are the single biggest practical performance difference between a naive implementation and a production one.
Conclusion
The model is the easy part. Given good weights, a forward pass is a function call. The hard part is everything the model sits on top of. The memory allocator decides which blocks to hand out, the scheduler decides which requests get in, and the engine keeps the GPU fed every single iteration.
What makes this space interesting right now is that it is still young. PagedAttention is two years old. Chunked prefill is newer. Speculative decoding is still being figured out. The gap between a naive serving setup and a well-tuned inference engine is often larger than the gap between model versions. Worth understanding from first principles.