
GitHub has a way of surfacing projects that make you stop mid-scroll. llama.cpp was one of those for me. A C/C++ LLM inference engine that lets you run language models locally, with Python bindings that call straight into the C++ core. I was hooked. But it raised a quiet question: how does Python actually call into compiled C++ code? What’s doing the connecting?
Turns out llama.cpp isn’t even the most extreme example. NumPy’s fastest routines are written in Fortran (before most of its users were born). The rusqlite crate ships three hundred thousand lines of C directly into your Rust binary. An intentional design. These languages produce code that higher-level runtimes simply can’t match. And the mechanism behind it fits in four steps.
The Pipeline Has Seams
Compilers, specifically the GCC (GNU Compiler Collection), provide the real magic here. The code execution pipeline has 4 stages.
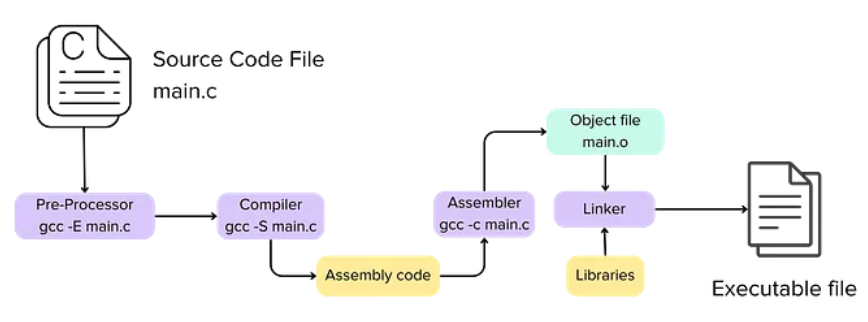 Preprocessing: Resolves macros, removes comments, and handles #include directives to prepare the code for compilation.
Preprocessing: Resolves macros, removes comments, and handles #include directives to prepare the code for compilation.
Compilation: Compilers often translate source code into an intermediate representation, like assembly.
Assembly: An assembler translates human-readable assembly instructions into machine code (ones and zeros), resulting in an object file.
Linking: The final stage where the linker combines various object files and external libraries into a single, self-contained executable.
Every language has its own “frontend”, the part that parses syntax, enforces types, and understands semantics. But many modern compilers share the same “backend”. For instance, when using Clang, C and C++ compile through LLVM. Rust and Swift do so by default. They each translate their source into LLVM Intermediate Representation (IR). LLVM IR is a typed, platform-agnostic assembly language. From that point on, the same optimizer and code generator run regardless of which language started the process. This means that Rust and C can share the same optimization passes, and thus essentially the same backend.
This pipeline can be stopped at any stage. This is what makes this whole process ubiquitous.
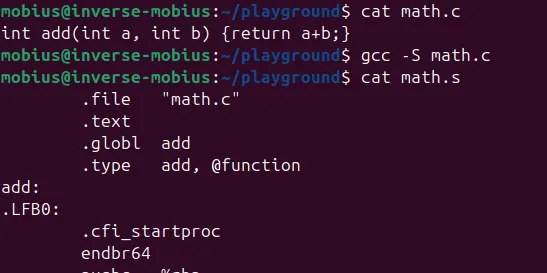
gcc -S math.c # Stop at assembly — outputs math.s, human-readable
gcc -c math.c # Stop at object file — outputs math.o, machine code + metadata
gcc math.c # Full pipeline — outputs a.out executable
That “math.o” object file is the atom of the multi-language world. Let's look inside one.
What’s Happening Here?
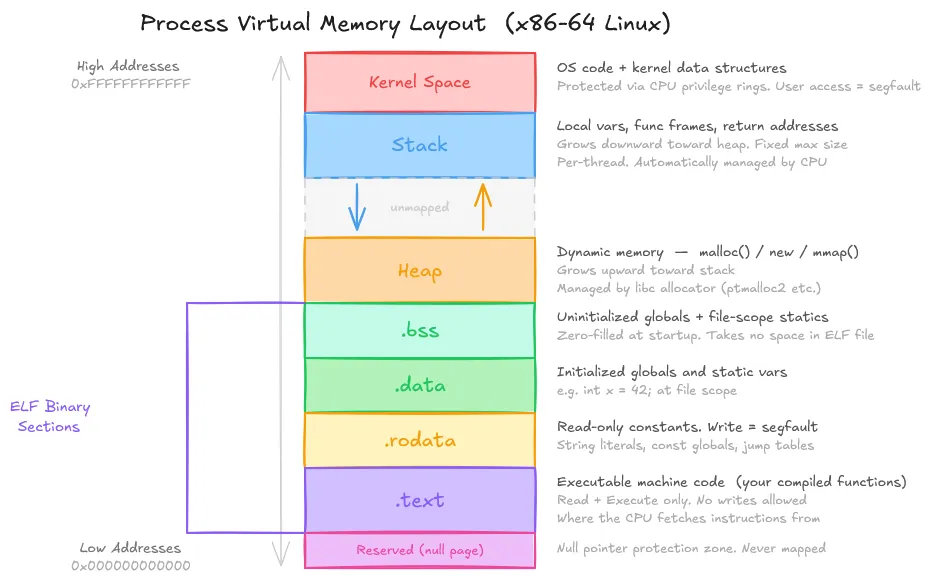
The symbol ‘add’ lives in the .text section. It is a function (F), globally visible (g), and 11 bytes long. But .text is just one of several sections in every object file. When the linker combines object files, it merges sections of the same type.
All the .text sections concatenate into one big block of code, all .data sections merge into one data region, so on. The output executable is a carefully arranged concatenation of sections from every object file the linker saw. This is the mechanical heart of what “linking” actually means.
Beyond the sections, each object file carries a symbol table, a directory of names mapped to locations within those sections. This is what the linker really reads, and it’s the key to multi-language linking. The symbol table has no field for “language of origin”. It is language agnostic.
The Linker Links It All
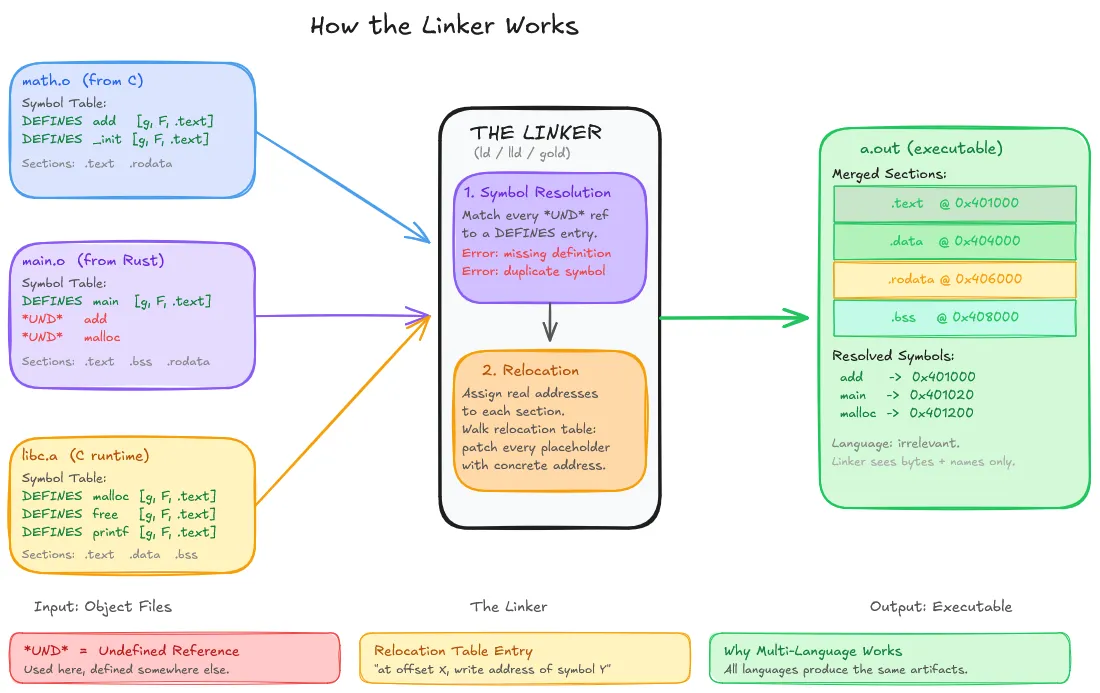 The Linker’s job is simple. It links everything into a single executable file. It takes a pile of object files, resolves all symbol references between them, fixes up addresses, and concatenates the result into an executable.
It doesn’t know or care that one object file came from C and another from Rust. It reads symbol tables, matches names, and brings it all together.
The Linker’s job is simple. It links everything into a single executable file. It takes a pile of object files, resolves all symbol references between them, fixes up addresses, and concatenates the result into an executable.
It doesn’t know or care that one object file came from C and another from Rust. It reads symbol tables, matches names, and brings it all together.
When your C code calls malloc, the compiler emits a reference to an external symbol named malloc. When the linker processes the C runtime library, it finds an object file that defines a symbol named malloc. It connects them. The languages that produced those two artifacts are irrelevant.
Symbol resolution is the process of matching every reference to a definition.
Relocation is the follow-on problem. When the compiler produces an object file, it doesn’t know where in memory the final executable will place that code. So it emits placeholder addresses alongside a relocation table.
The linker resolves all symbols, decides the layout of every section in the final binary, then walks the relocation tables and fixes up every placeholder. At the end, every address is concrete.
This architecture, which compiles separately and then links, was designed so that changing one source file requires only recompiling that file. Multi-language linking is the identical mechanism, extended across language boundaries.
Name Mangling: Why Symbol Names Break Across Languages
The linker matches symbols by name. But doing just this could present a problem in the case of function overloading.
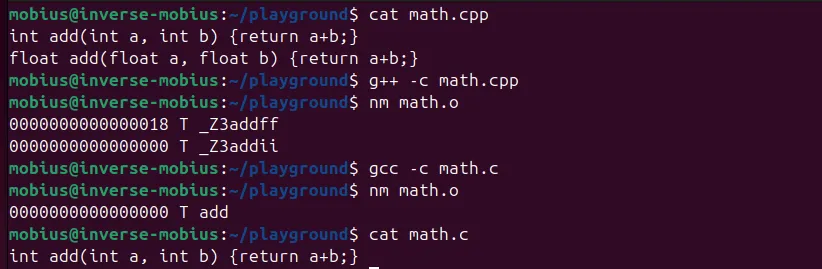
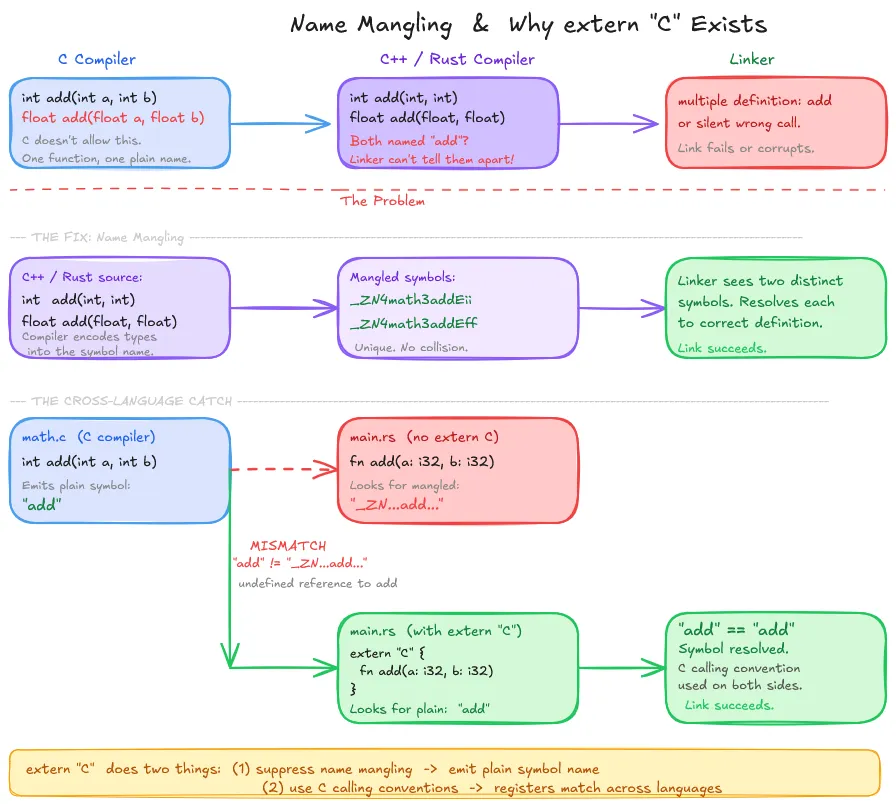
While C doesn’t support function overloading, so its compiler can emit a symbol “add” for a function add(). But C++ and Rust do support function overloading. What would happen if you had a function int add(int, int) and float add (float, float) in the same file?
At the machine level, these need different names for the linker to tell them apart.
C++ solves this by encoding type information into the symbol name itself. A mangled identifier that encodes the namespace, function name, and parameter types. Rust does the same, adding hash-based disambiguation on top.
This is why “extern C” exists. When you declare extern “C” in Rust or C++, you’re telling the compiler two things: use C calling conventions and suppress name mangling, emitting the plain, undecorated symbol name.
Without that second part, Rust emits a reference to some mangled name, C emits a definition under the plain name, and the linker sees two unrelated symbols. The link fails, or worse, silently succeeds if the mangled name accidentally collides with something else.
// math.c — C always emits the plain name: "add"
int add(int a, int b) {
return a + b;
}
---------------------------------------------------------------------------------------------------
// main.rs
extern "C" {
// Without extern "C", Rust would look for a mangled symbol, not "add".
// extern "C" says: match the plain C name AND use C calling conventions.
fn add(a: i32, b: i32) -> i32;
}
---------------------------------------------------------------------------------------------------
fn main() {
let result = unsafe { add(5, 3) };
println!("Result: {}", result);
}
---------------------------------------------------------------------------------------------------
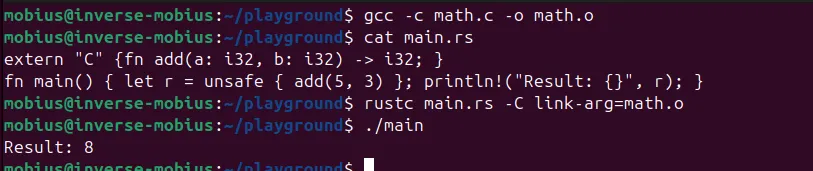
# Compile C to object file
gcc -c math.c -o math.o
# Compile Rust, linking against the C object file
rustc main.rs -C link-arg=math.oo
The extern "C" annotation is doing double duty that most tutorials don't spell out. Calling convention correctness is one-half. Name compatibility is the other, and it's equally load-bearing.
ABI: The Contract Nobody Told You About
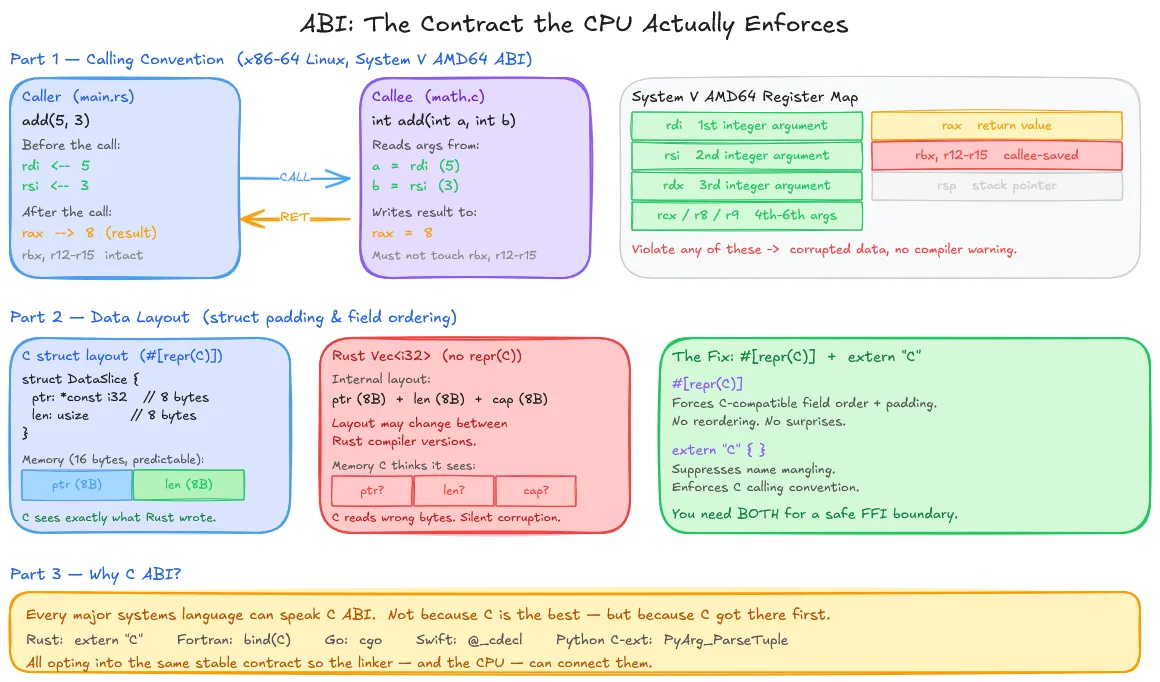 Matching symbol names gets you to the right function. But getting to the right function and correctly executing it are two different things.
An API is a contract at the source level: “this function takes two ints and returns an int”. An ABI (Application Binary Interface) is a contract at the machine level.
Matching symbol names gets you to the right function. But getting to the right function and correctly executing it are two different things.
An API is a contract at the source level: “this function takes two ints and returns an int”. An ABI (Application Binary Interface) is a contract at the machine level.
The API is what you write. The ABI is what the CPU actually sees.
The most important ABI component is the calling convention. It is the agreed-upon protocol for function calls.
The second component is data layout: how structs are arranged in memory. C compilers insert padding between fields to satisfy alignment requirements.
The #[repr(C)] attribute and the extern "C" block is both ABI annotations. The first controls data layout; the second controls calling convention and symbol naming. You need both for correct cross-language boundaries.
Static vs. Dynamic Linking: The Runtime Dimension
Everything described so far, the linker consuming object files, resolving symbols, fixing up addresses, describes static linking. The executable produced contains all the machine code it needs. But this isn’t how most real-world cross-language interop works.
When Python calls a NumPy C extension, it doesn’t link against NumPy at Python’s compile time. It loads a .so file (shared object) on Linux, .dylib on macOS, .dll on Windows, at runtime. This is dynamic linking.
With dynamic linking, the linker’s work is deferred.
The first call to a dynamically linked function actually calls a small stub that resolves the address on demand and caches it. Subsequent calls hit the cache address directly.
The practical implication: the multi-language pattern that seems like wizardry in the wild isn't feasible with static linking (Rust statically linking a C object file). It's a high-level language runtime loading a .so compiled code from C or C++, communicating through a C ABI boundary. More on PLT/GOT
When and Why to Use This
The well-known and preferred pattern: performance-critical code in a compiled systems language, orchestration logic in a higher-level one, is everywhere serious software is built.
The Python data science ecosystem is a thin Python layer over C and Fortran numerical kernels. React Native bridges JavaScript to C++ native UI code. LuaJIT embeds inside game engines written in C++.
The reason is obvious. You don’t rewrite a battle-tested, hand-optimized FFT routine just because your application logic is more convenient to express in a different language. You write the hot loop once, compile it to an object file or shared library, expose it through a C ABI boundary, and call it from wherever your orchestration code lives.
TL;DR: Every compiled language is ultimately a different way of generating the same thing: machine code in object files with symbol tables. The linker assembles them without knowing what language produced them, as long as everyone agrees on symbol names and how to talk to each other at runtime. ABIs and Dynamic Linking make the process smoother.